BIOS IT Blog
SC19 News Roundup
INTEL®
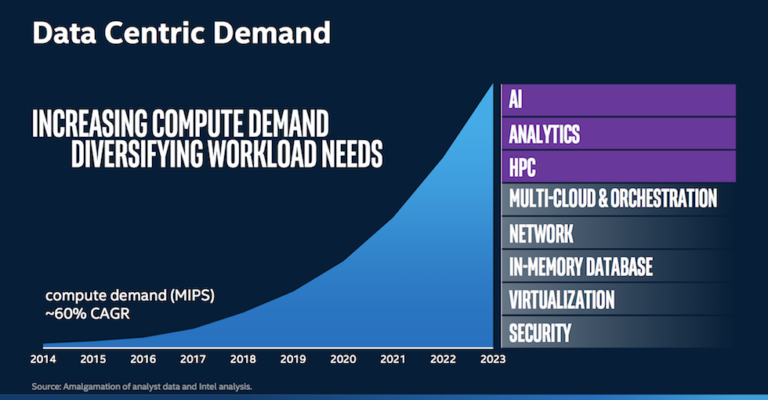
Intel® revealed a few more details about its forthcoming Xe line of GPUs – the top SKU is named Ponte Vecchio and will be used in Aurora, the first planned U.S. exascale computer. Intel® is targeting the high-performance computing (HPC) and AI segments with both the GPU and a new software initiative that aims to shift away from “single-architecture, single-vendor” programming models.
“No longer [does] one size fit all,” said Intel’s Raj Hazra, VP & GM for enterprise and government.“We have to look at architectures tuned to the needs of varying kinds of workloads in this convergence era.”
Ponte Vecchio will be fabricated on Intel's forthcoming 7nm node, and not its troubled 10nm process. It will use Chipzilla's exascale Xe architecture and Foveros and EMIB packaging, and support high-bandwidth cache and memory and CXL-based interconnects.
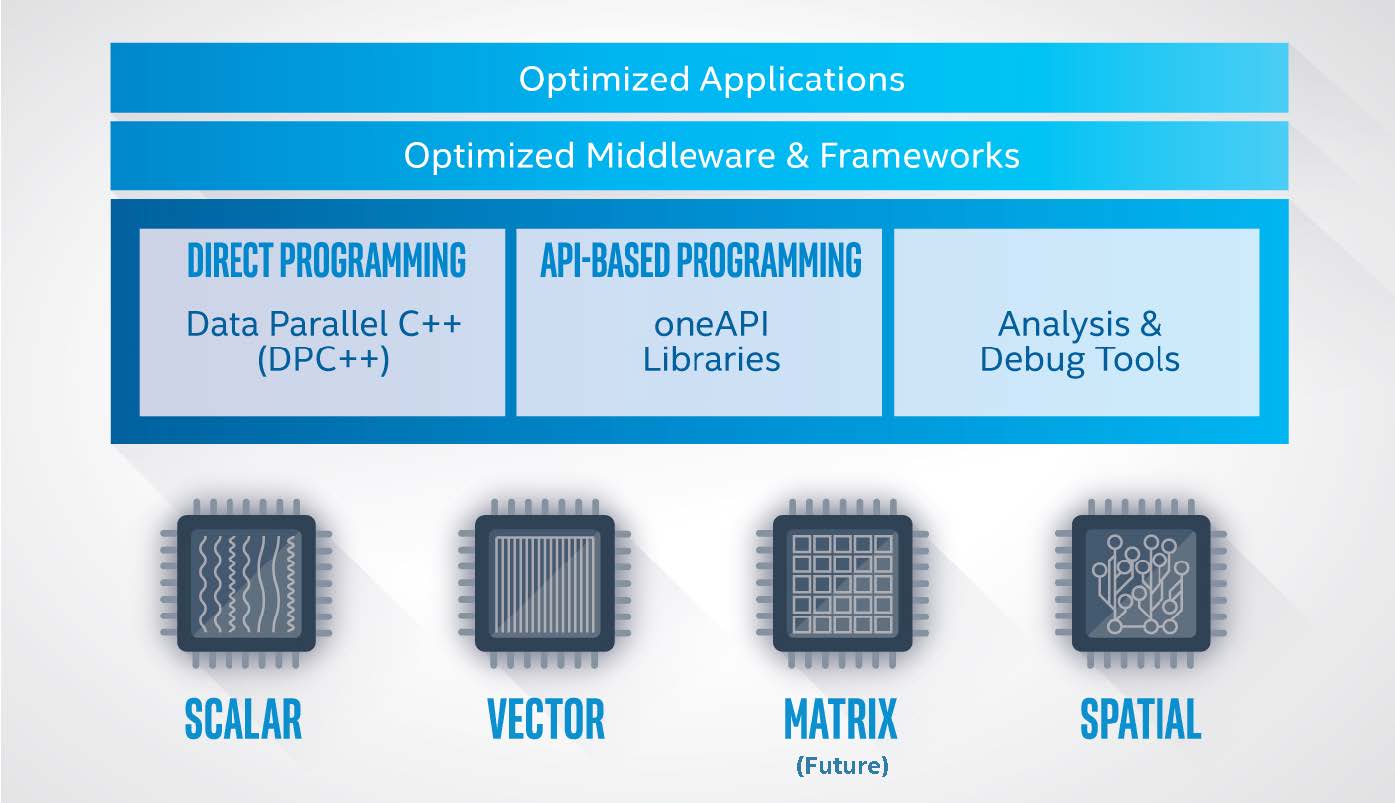
Intel also took time to dig deeper into its oneAPI effort which is now in “beta launch” and positioned as both an industry initiative and an Intel product intended to enhance development for heterogeneous compute architectures.
One API’s powerful libraries span several workload domains that benefit from acceleration. Library functions are custom-coded for each target architecture; it allows programming from a single code base with native high-level language performance across architectures like Scalar, Vector, Matrix & Spatial. Building on leading analysis tools, Intel will deliver enhanced versions of analysis and debug tools to support DPC++ and the range of SVMS architectures. Find out more here.
NVIDIA®
NVIDIA® made a number of important announcements at SC19, including an introduction to its reference design platform that enables customers to quickly build GPU-accelerated Arm-based servers, driving a new era of high-performance computing for a growing range of applications in science and industry. The lack of a clear accelerator strategy has been a major stumbling block for Arm push to penetrate HPC and enterprise data centres. Arm chips are among the most-used in the world for many embedded and small devices applications. Advocates have always cited lower power as an advantage over x86. Gopal Hegde, VP/GM, Server Processor Business Unit, for Arm chip designer Marvel which collaborated with Nvidia on the Cuda work, estimates the power reduction advantage is 15%-to-18% on comparable chips.

“There is a renaissance in high performance computing,” Huang said. “Breakthroughs in machine learning and AI are redefining scientific methods and enabling exciting opportunities for new architectures. Bringing NVIDIA GPUs to Arm opens the floodgates for innovators to create systems for growing new applications from hyperscale-cloud to exascale supercomputing and beyond.”
The next big news from NVIDIA® was their intro to NVIDIA® Magnum IO, a suite of software to dramatically accelerate data processing by eliminating storage and input/output bottlenecks. The Magnum IO suite is anchored by GPUDirect, which provides a path for data to bypass CPUs and travel on “open highways” offered by GPUs, storage and networking devices. Optimised to eliminate storage and input/output bottlenecks, Magnum IO delivers up to 20x faster data processing for multi-server, multi-GPU computing nodes when working with massive datasets to carry out complex financial analysis, climate modelling and other HPC workloads.
AMD
AMD announced a set of new customer wins and new platforms supporting AMD EPYC™ processors and Radeon Instinct accelerators, as well as the release of ROCm 3.0 development environment. HPC organizations are continuing to adopt the 2nd Gen AMD EPYC processor and Radeon Instinct accelerators for more powerful and efficient supercomputing systems. The 2nd Gen EPYC processors provide twice the manufacturing application performance and up to 60% faster Life Sciences simulations than competing solutions, while the Radeon Instinct GPU accelerator provides up to 6.6 peak theoretical TFLOPS Double Precision performance for HPC workloads. Both products support PCIe® 4.0 enabling high-bandwidth interconnect for faster compute across heterogeneous systems.

To find out more about any of the above solutions and announcements, please contact us.
Not what you're looking for? Check out our archives for more content
Blog Archive
From Silicon to Cloud
Turnkey IT Solutions that scale to meet customers needs




